Ransomware groups are coming and going faster than ever. In June alone we saw Avaddon release its decryption keys unprompted and disappear from sight, while members of CLOP were arrested in Ukraine. The move follows increasing pressure from the US intelligence community and Ukrainian authorities, who took down Egregor ransomware back in February. Egregor had only been around since September 2020. It survived less than six months.
But these gangs aren’t going away – they are simply going underground. Despite ‘closures’, cases of ransomware continue to rise and new threat actors and independent hackers pop up on the Dark Web every day.
As malware actors lay low and resurface with new variants, keeping up with the stream of signatures and new strains has become untenable. This blog studies the techniques, tools and procedures (TTPs) observed from a real-life Egregor intrusion last autumn, which showcases how Self-Learning AI detected the attack without relying on signatures.
Egregor: Maze reloaded

Law enforcement authorities have been busy this year. Aside from Egregor and CLOP, actions were taken against Netwalker in Bulgaria and the US, while Europol announced that an international operation had disrupted the core infrastructure of Emotet, one of the most prominent botnets of the past decade.
All parties – from governments down to individual businesses – are taking the threat of ransomware more seriously. In response to this added pressure, cyber-criminals often prefer to shut up shop rather than hang around long enough to be arrested.
DarkSide famously closed down after the Colonial Pipeline attacks, only nine months after it had been created. An admin from the Ziggy gang announced that it would issue refunds and was looking for a job as a threat hunter.
“Hi. I am Ziggy ransomware administrator. We decided to publish all decryption keys.
We are very sad about what we did. As soon as possible, all the keys will be published in this channel.”
Take this apology with a pinch of salt. The players which have ‘closed down’ have not had a change of heart, they’ve just changed tack. Different names and new infrastructure can help keep the heat off and circumvent US sanctions or federal scrutiny. PayloadBIN (a new ransomware which cropped up last month), WastedLocker, Dridex, Hades, Phoenix, Indrik Spider… all just aliases for one single group: Evil Corp.
The FBI are becoming more aggressive in their methods of infiltration and disruption, so it is likely we will see more of these U-turns and guerrilla-style tactics. Temporary pop-up gangs are an emerging trend in place of large, established enterprises like REvil, whose websites also vanished following the attack against Kaseya. And there is no doubt we will continue to witness these ‘exit scams’, where groups retire and re-brand, like Maze did last September, when it came back as Egregor.
Darktrace detects malware regardless of the name or strain. It stopped Maze last year, and, as we shall see below, it stopped its successor Egregor, even though the code and C2 endpoints used in the intrusion had never been seen before.

Egregor ransomware attack
Back in November 2020, Egregor was in full bloom, targeting major organizations and exfiltrating data in ‘double extortion’ attacks. At a logistics company in Europe with around 20,000 active devices, during a Darktrace Proof of Value (POV) trial, Egregor struck.

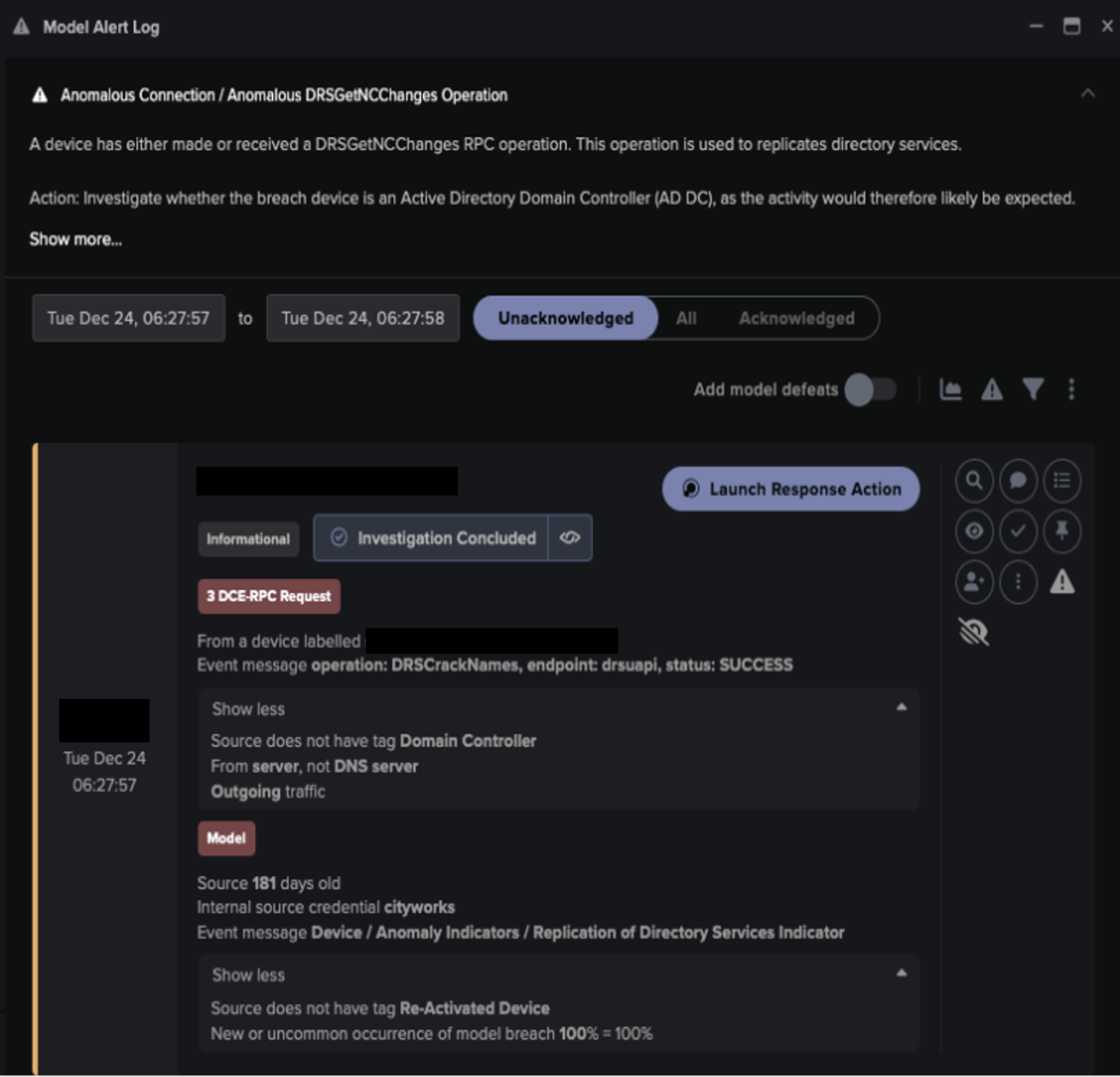
Figure 1: Timeline of the attack. The overall dwell time — from first C2 connection to encryption — was five days.
As a Ransomware-as-a-Service (RaaS) gang, it appears Egregor had partnered with botnet providers to facilitate initial access. In this case, the compromised device carried signs of prior infection. It was seen connecting to an apparent Webex endpoint, before connecting to the Akamai doppelganger, amajai-technologies[.]network. This activity was followed by a number of command and control (C2) and exfiltration-related breaches.
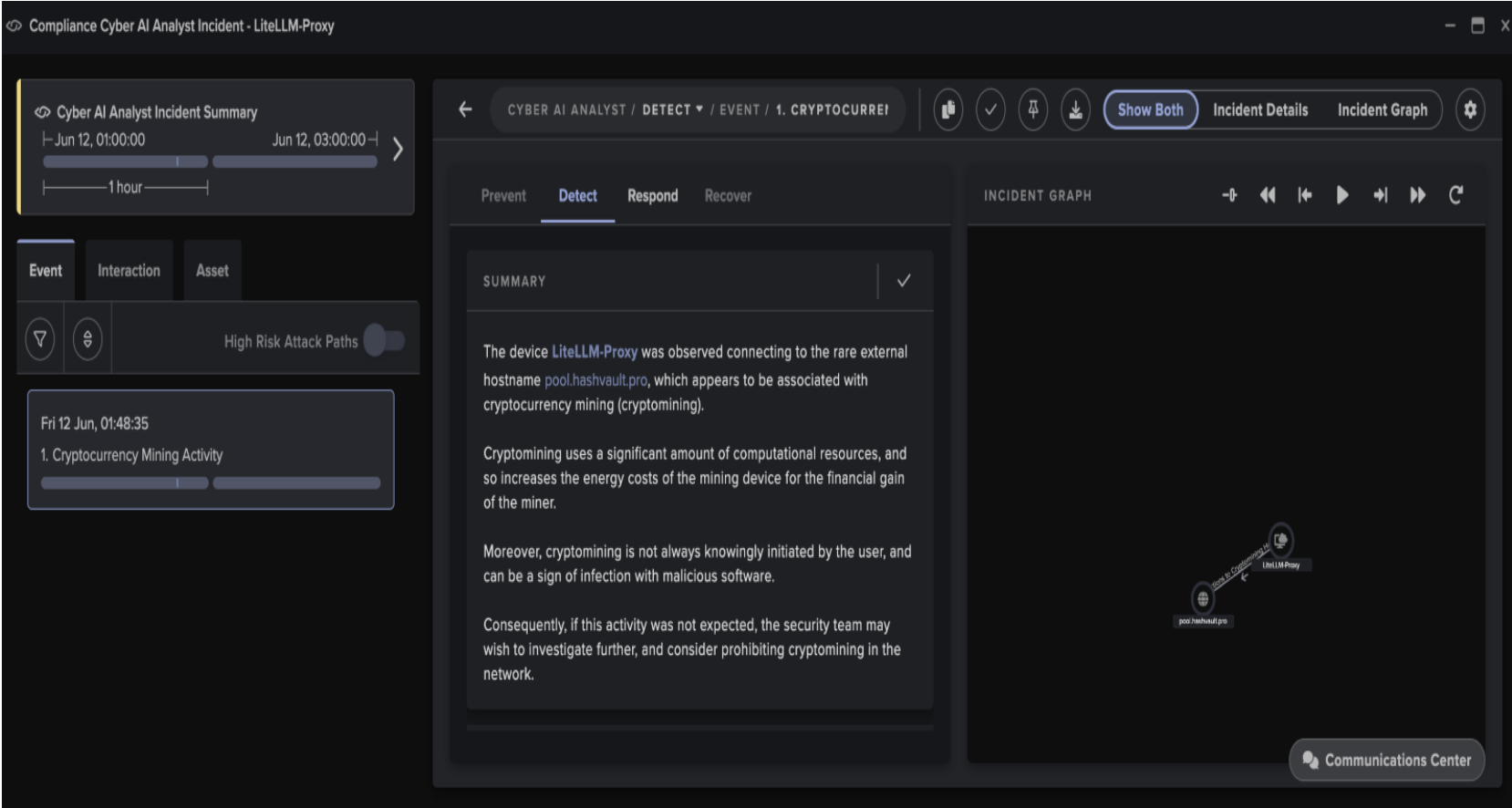
Three days later, Darktrace observed lateral movement over HTTPS. Another device – a server – was seen connecting to the amajai host. This server wrote unusual numeric exectuables to shared SMB drives and took new service control. A third host then made a ~50GB upload to a rare IP.

Figure 2: Cyber AI Analyst summarizes the initial C2 and unusual SMB writes in a similar incident, followed later by a large upload to a rare external endpoint.
After two days, encryption began. This triggered multiple hosts breaches. On the final day, the attacker made large uploads to various endpoints, all from ostensibly compromised hosts.
Retrospective analysis

If the attack had not been neutralized at this point, it could have resulted in significant financial loss and reputational damage for the company. The two-pronged attack enabled Egregor both to encrypt critical resources and to exfiltrate them, with a view to publicizing sensitive data if the victims refused to pay up.
The affiliates who deployed the ransomware in this case were highly skilled. They leveraged a number of sophisticated techniques including the use of a large number of C2 endpoints, with doppelgangers and off-the-shelf tools.
The adoption of HTTPS for lateral movement and reconnaissance reduced lateral noise for scans and enumeration. The complex C2 had numerous endpoints, some of which were doppelgangers of legitimate sites. Furthermore, some malware was downloaded as masqueraded files: the mimetype Octet Streams were downloaded as ‘g.pixel’. These three tactics helped obfuscate the attacker’s movements and trick traditional security tools.
Ransomware attacks are occurring at a speed that even five years ago was unimaginable. In this case, the overall dwell time was less than a week, and part of the attack happened out of office hours. This highlights the need for Autonomous Response, which can keep up with novel threats and does not rely on humans being in the loop to contain cyber-attacks.
Gone today, here tomorrow
Egregor was busted in February, but we may well see it resurface under a different name and with modified code. If and when this happens, signatures will be of no use. Catching never-before-seen ransomware, which employs novel methods of intrusion and extortion, requires a different approach.
The endpoint in the case study above is now associated via open-source intelligence (OSINT) with Cobalt Strike. But at the time of the investigation, the C2 was unlisted. Similarly, the malware was unknown to OSINT and thus evaded signature-based tools.
Despite this, Self-Learning AI detected every single stage of the in-progress attack. No action was taken as it was only a trial POV so Darktrace had no remote access in the environment. However, after seeing the power of the technology, the organization decided to implement Darktrace across its digital estate.
Thanks to Darktrace analyst Roberto Romeu for his insights on the above threat find.
Learn how Darktrace stops Egregor and all forms of ransomware
Darktrace model detections:
- Agent Beacon to New Endpoint
- Agent Beacon (Long Period)
- Agent Beacon (Medium Period)
- Agent Beacon (Short Period)
- Anomalous Octet Stream
- Anomalous Server Activity / Outgoing from Server
- Anomalous SMB Followed By Multiple Model Breaches
- Anomalous SSL without SNI to New External
- Beaconing Activity To External Rare
- Beacon to Young Endpoint
- Data Sent To New External Device
- Data Sent to Rare Domain
- DGA Beacon
- Empire Python Activity Pattern
- EXE from Rare External Location
- High Volume of Connections with Beacon Score
- High Volume of New or Uncommon Service Control
- HTTP Beaconing to Rare Destination
- Large Number of Model Breaches
- Long Agent Connection to New Endpoint
- Low and Slow Exfiltration
- Multiple C2 Model Breaches
- Multiple Connections to New External TCP Port
- Multiple Failed Connections to Rare Endpoint
- Multiple Lateral Movement Model Breaches
- Network Scan
- New Failed External Connections
- New or Uncommon Service Control
- Numeric Exe in SMB Write
- Rare External SSL Self-Signed
- Slow Beaconing Activity To External Rare
- SMB Drive Write
- SMB Enumeration
- SSL Beaconing to Rare Destination
- SSL or HTTP Beacon
- Suspicious Beaconing Behaviour
- Suspicious Self-Signed SSL
- Sustained SSL or HTTP Increase
- Quick and Regular Windows HTTP Beaconing
- Uncommon 1 GiB Outbound
- Unusual BITS Activity
- Unusual Internal Connections
- Unusual SMB Version 1 Connectivity
- Zip or Gzip from Rare External Location