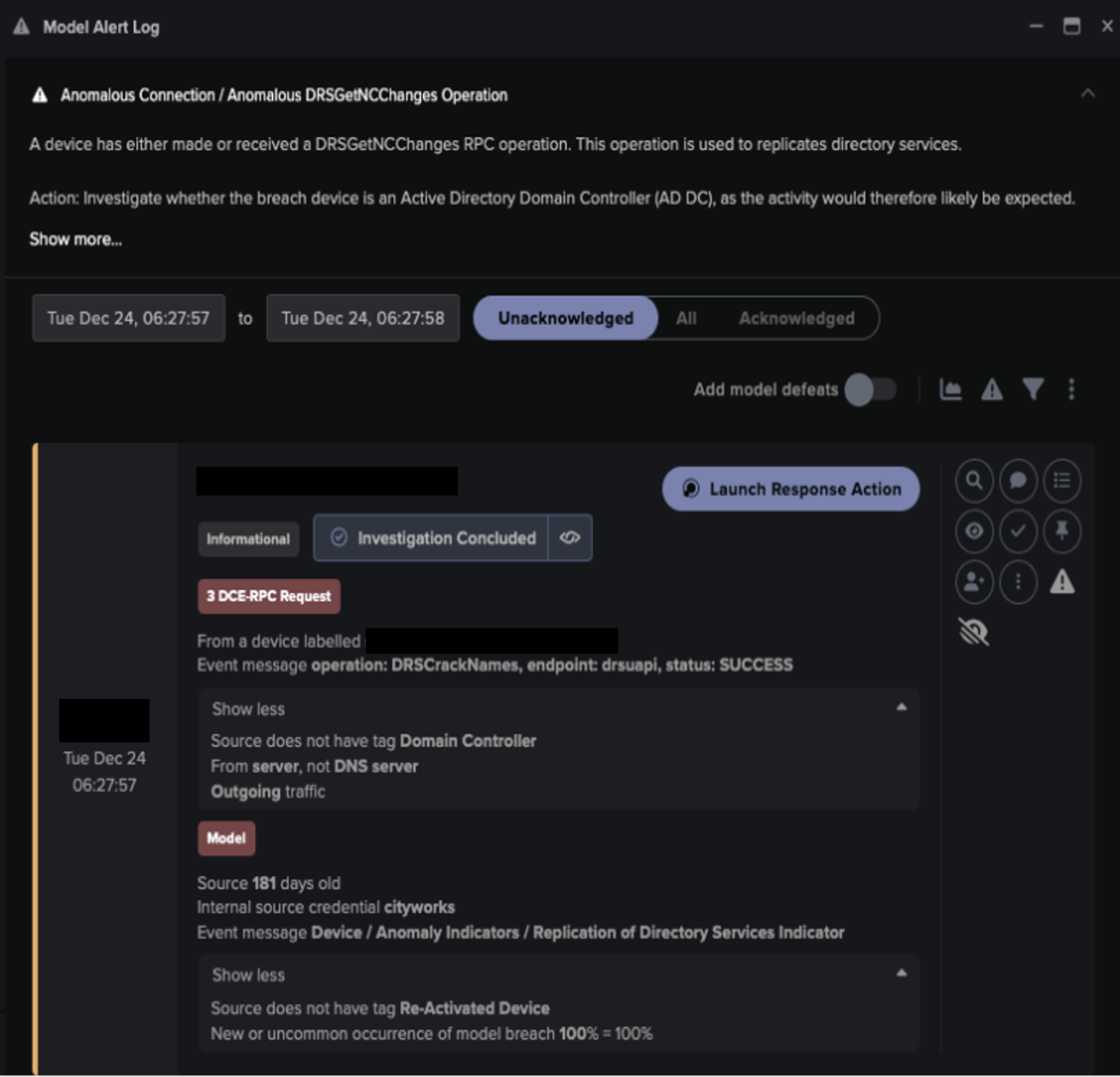
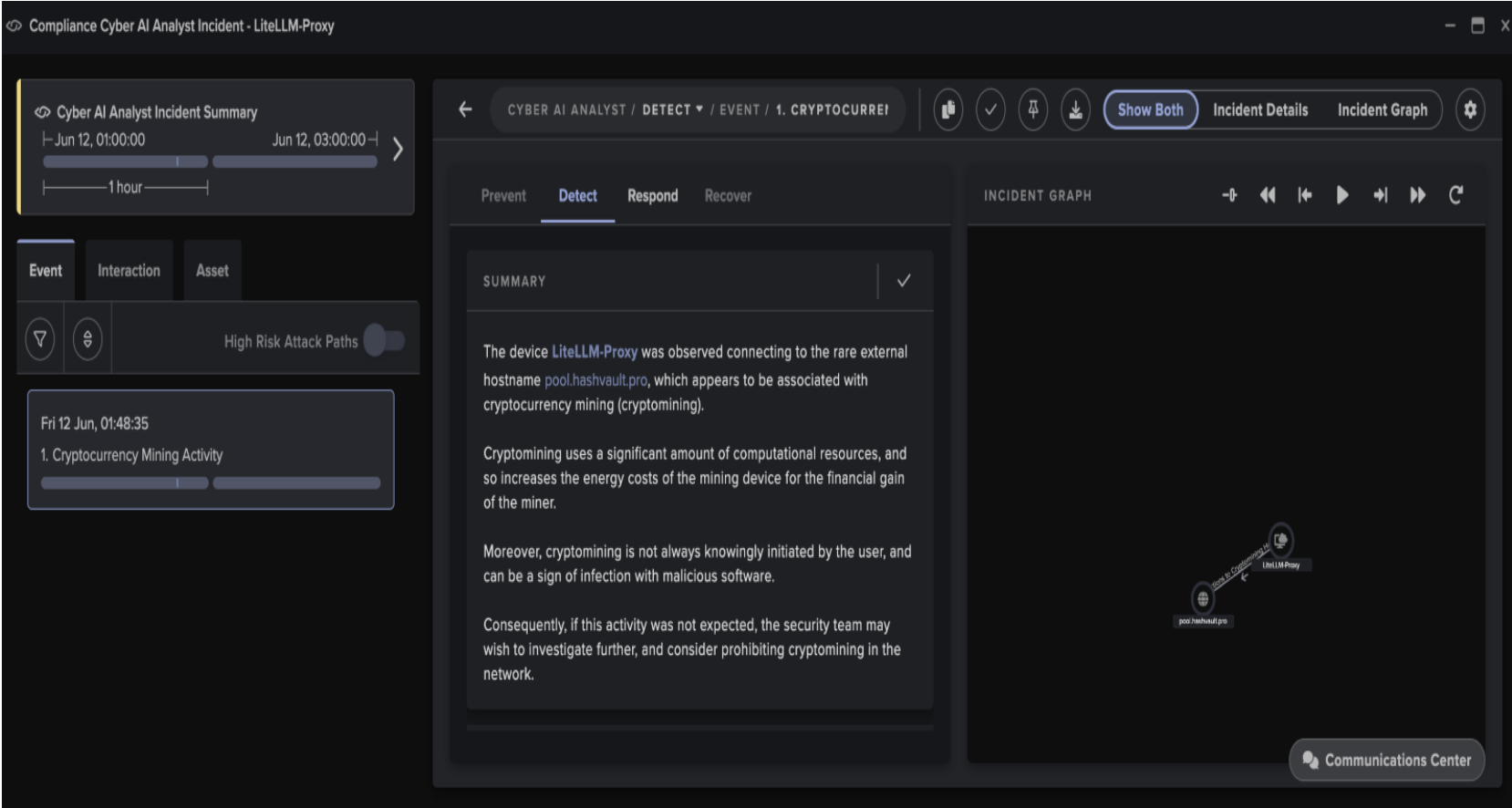
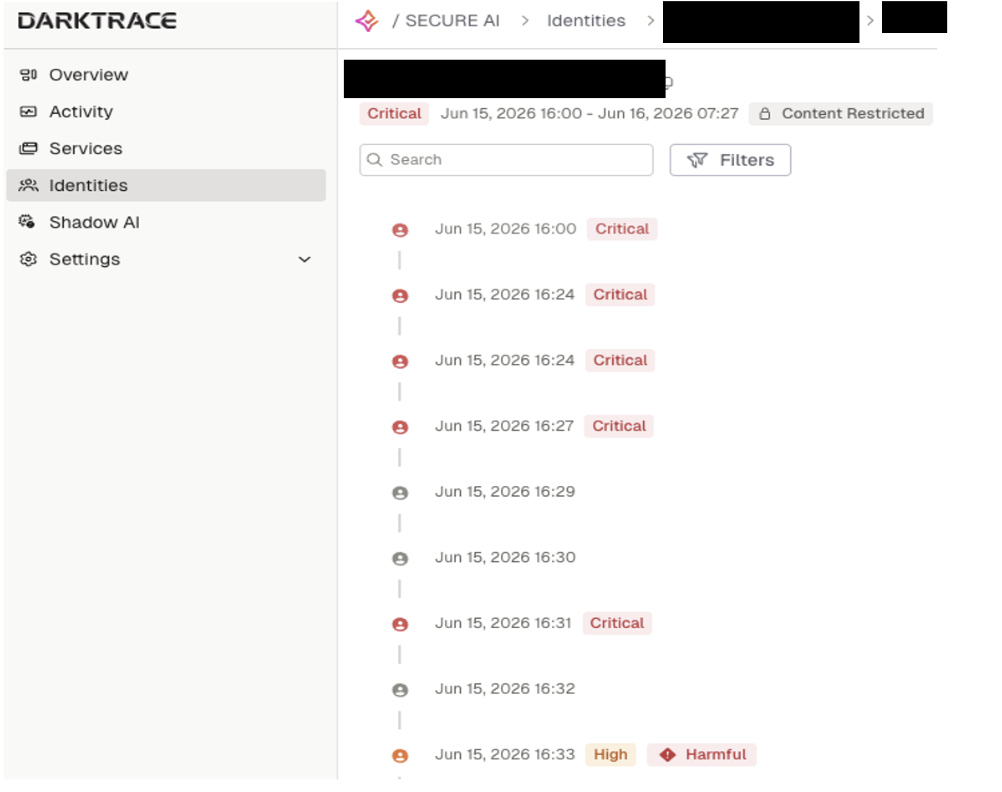
The findings in this blog are taken from Darktrace's annual State of AI Cybersecurity Report 2026.
AI is already embedded in day-to-day enterprise activity, with 78% of participants in one recent survey reporting that their organizations are using generative AI in at least one business function. Generative AI now acts as an always-on assistant, researcher, creator, and coach across an expanding array of departments and functions. Autonomous agents are performing multi-step operational workflows from end to end. AI features have been layered on top of every SaaS application. And vibe coding is making it possible for employees without deep technical expertise to build their own AI-powered automations.
According to Gartner, more than 80% of enterprises will have deployed GenAI models, applications, or APIs in production environments by the end of this year, up from less than 5% in 2023. Companies report a 130% increase in spending on AI over the same period, with 72% of business leaders using AI tools at least weekly. The outsized efficiency and productivity gains that were once a future vision are quickly becoming everyday reality.
AI is currently driving business growth and innovation, and organizations risk falling behind peers if they don’t keep up with the pace of adoption, but it is also quietly expanding the enterprise attack surface. The modern CISO is challenged to both enable innovation and protect the business from these emerging threats.
AI agents introduce new risks and vulnerabilities
AI agents are playing growing roles in enterprise production environments. In many cases, these agents act with broad permissions across multiple software systems and platforms. This means they’re granted far-reaching access – to sensitive data, business-critical applications, tokens and APIs, and IT and security tools. With this access comes risk for security leaders – 92% are concerned about the use of AI agents across the workforce and their impact on security.
These agents must be governed as identities, with least-privilege access and ongoing monitoring. They can’t be thought of as invisible aspects of the application estate. Understanding how AI agents behave, and how to manage their permissions, control their behavior, and limit their data access will be a top security priority throughout 2026.
Generative AI prompts: The next frontier
Prompts are how users – both human and agentic – interact with AI systems, and they’re where natural language gets translated into model behavior. Natural language is infinite in its potential combinations and permutations, making this aspect of the attack surface open-ended and far more complex than traditional CVEs. With carefully crafted prompts, bad actors may be able to coax models into disclosing sensitive data, bypassing guardrails, or initiating undesirable actions.
Among security leaders, the biggest worries about AI usage in their environments all involve ways that systems might be manipulated to bypass traditional controls.
- 61% are most concerned about the exposure of sensitive data
- 56% are most concerned about potential data security and policy violations
- 51% are most concerned about the misuse or abuse of AI tools
The more employees rely on AI in their day-to-day workflows, the more critical it becomes for security teams to understand how prompt behavior determines model behavior – and where that behavior could go wrong.
What does “securing AI” mean in practice?
AI adoption opens new security risks that blur the boundaries between traditional security disciplines. A single malicious interaction with an AI model could involve identity misuse, sensitive data exposure, application logic abuse, and supply chain risk – all within a single workflow. Protecting this dynamic and rapidly evolving attack surface requires an approach that spans identity security, cloud security, application security, data security, software development security, and more.
The task for security leaders is to implement the tools, policies, and frameworks to mitigate these novel, expansive, and cross-disciplinary risks.
However, within most enterprises, AI policy creation remains in its infancy. Just 37% of security leaders report that their organization has a formal AI policy, representing a small but worrisome decrease from last year. Conversations about AI abound: in 52% of organizations, there’s discussion about an AI policy. Still, talk is cheap, and leaders will need to take action if they’re to successfully enable secure AI innovation.
To govern and protect their AI systems, organizations must take a multi-pronged approach. This requires building out policies, but it also demands that they are able to:
- Monitor the prompts driving GenAI assistants and agents in real time. Organizations must be able to inspect prompts, sessions, and responses across enterprise GenAI tools, low- and high-code environments, and SaaS and SASE so that they can detect clever conversational prompt attacks and malicious chaining.
- Secure all business AI agent identities. Security teams need to identify all the agents acting within their environment and supply chain, map their connections and interactions via MCP and services like Amazon S3, and audit their behavior across the cloud, SaaS environments, and on the network and endpoint devices.
- Maintain centralized, comprehensive visibility. Understanding intent, assessing risks, and enforcing policies all require that security teams have a single view that spans AI interactions across the entire business.
- Discover and control shadow AI. Teams need to be able to identify unsanctioned AI activities, distinguish the misuse of legitimate tools from their appropriate use, and apply policies to protect data, while guiding users towards approved solutions.
Scaling AI safely and responsibly
The approach that most cybersecurity vendors have taken – using historical patterns to predict future threats – doesn’t work well for AI systems. Because AI changes its behavior in response to the information it encounters while taking action, previous patterns don’t indicate what it will do next. Looking at past attacks can’t tell you how complex models will behave in your individual business.
Securing AI requires interpreting ambiguous interactions, uncovering subtleties that reveal intent within extended conversations, understanding how access accumulates over time, and recognizing when behavior – both human and machine – begins to drift towards areas of risk. To do this, you need to understand what “normal” looks like in each unique organization: how users, systems, applications, and AI agents behave, how they communicate, and how data flows between them.
Darktrace has spent more than a decade designing AI-powered solutions that can understand and adapt to evolving behavior in complex environments. This technology learns directly from the environment it protects, identifying malicious actions that deviate from normal operations, so that it can stop AI-related threats on the very first encounter.
As AI adoption reshapes enterprise operations, humans and machines will collaborate more and more often. This collaboration might dramatically expand the attack surface, but it also has the potential to be a force multiplier for defenders.
Explore the full State of AI Cybersecurity 2026 report for deeper insights into how security leaders are responding to AI-driven risks.
Learn more about securing AI in your enterprise.
[related-resource]
Get the State of AI Cybersecurity 2026 Report
Explore how the rapid adoption of AI is reshaping cyber risk worldwide in our annual landmark survey on AI in the cybersecurity industry.