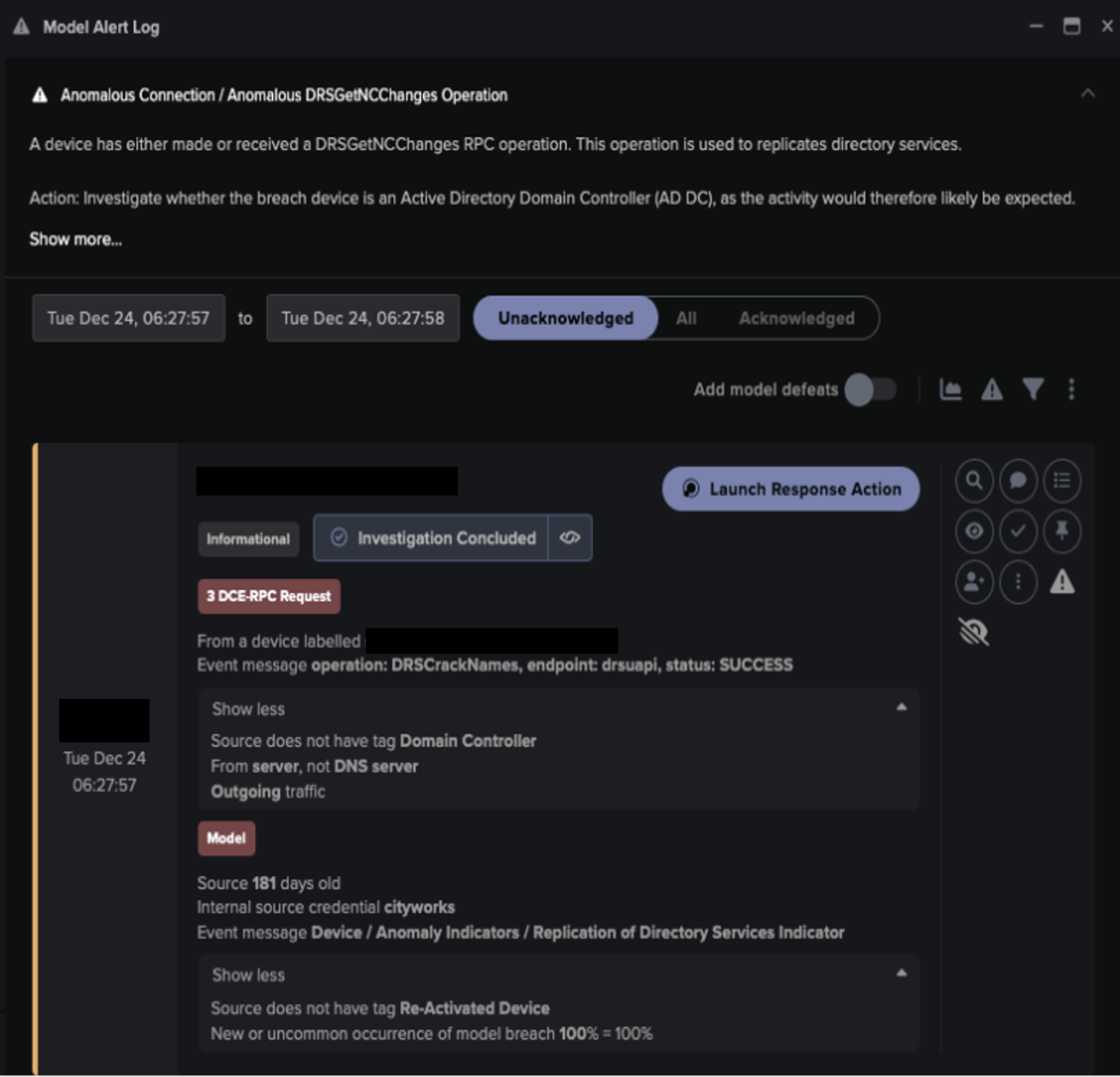
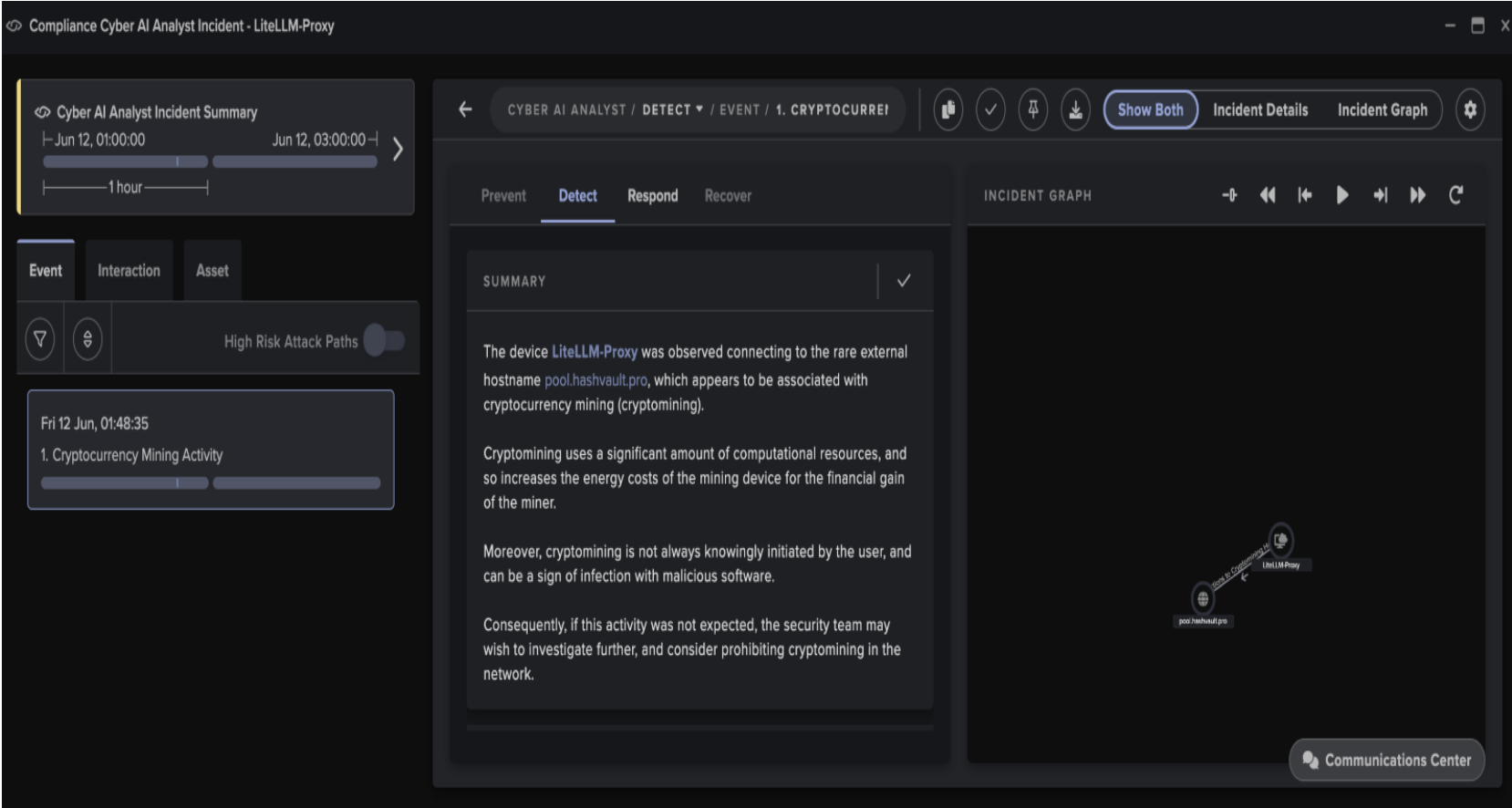
What’s the problem with an attack-centric mindset?
For decades, traditional email security strategies have been built around an attack-centric mindset. Secure Email Gateways (SEGs) and other legacy solutions operate on the principle of identifying and blocking known threats. These systems rely heavily on predefined threat intelligence – blacklists, malware signatures, and reputation-based analysis – to filter out malicious content before it reaches the inbox.
While this approach was sufficient when email threats were relatively static and signature-based, it’s increasingly ineffective against the sophistication of modern attacks. Techniques like spear phishing, business email compromise (BEC), and supply chain attacks often bypass traditional SEG defenses because they lack obvious malicious indicators. Instead, they leverage social engineering, look-alike domains, and finely tuned spoofing tactics that are designed to evade detection.
The challenge extends beyond just legacy SEGs. Many modern email security providers have inherited the same attack-centric principles, even if they've reimagined the technology stack. While some vendors have shifted to API-based deployments and incorporated AI to automate pattern recognition, the underlying approach remains the same: hunting for threats based on known indicators. This methodology, though it’s undergone modernization using AI, still leaves gaps when it comes to novel, hyper-targeted threats that manipulate user behavior rather than deploy predictable malicious signatures. Attack-centric security will always remain one step behind the attacker.
By the way, native email security already covers the basics
One of the most overlooked realities in email security is that native solutions like Microsoft 365’s built-in security already handle much of the foundational work of attack-centric protection. Through advanced threat intelligence, anti-phishing measures, and malware detection, Microsoft 365 actively scans incoming emails for known threats, using global telemetry to identify patterns and block suspicious content before it even reaches the user’s inbox.
This means that for many organizations, a baseline level of protection against more obvious, signature-based attacks is already in place – but many are still disabling these protections in favour of another attack-centric solution. By layering another attack-centric solution on top, they are effectively duplicating efforts without enhancing their security posture. This overlap can lead to unnecessary complexity, higher costs, and a false sense of enhanced protection when in reality, it’s more of the same.
Rather than duplicating attack-centric protections, the real opportunity lies in addressing the gaps that remain: the threats that are specifically crafted to evade traditional detection methods. This is where a business-centric approach becomes indispensable, complementing the foundational security that’s already built into your infrastructure.
Introducing… the business-centric approach
To effectively defend against advanced threats, organizations need to adopt a business-centric approach to email security. Unlike attack-centric models that hunt for known threats, business-centric security focuses on understanding the typical behaviors, relationships, and communication patterns within your organization. Rather than solely reacting to threats as they are identified, this model continuously learns what “normal” looks like for each user and each inbox.
By establishing a baseline of expected behaviors, business-centric solutions can rapidly detect anomalies that suggest compromise, such as sudden changes in sending patterns, unusual login locations, or subtle shifts in communication tone. This proactive detection method is especially powerful against spear phishing, business email compromise (BEC), and supply chain attacks that are engineered to bypass static defenses. This approach also scales with your organization, learning and adapting as new users are onboarded, communication patterns evolve, and external partners are added.
In an era where AI-driven threats are becoming the norm, having email security that knows your users and inboxes better than the attacker does is a critical advantage.
Why native + business-centric email security is the winning formula
By pairing native security with a business-centric model, organizations can cover the full spectrum of threats – from signature-based malware to sophisticated, socially engineered attacks. Microsoft 365’s in-built security manages the foundational risks, while business-centric defense identifies subtle anomalies and targeted threats that legacy approaches miss.
.avif)
Rather than layering redundant attack-centric solutions on top of existing protections, the future of email security lies in leveraging what’s already in place and building on it with smarter, behavior-based detection. The Swiss Cheese Model is a useful one to refer to here: by acknowledging that no single defense can offer complete protection, layering defenses that plug each other’s gaps – like slices of Swiss cheese – becomes critical.
This combination also allows security teams to focus their efforts more effectively. With native solutions catching broad-based, known threats, the business-centric layer can prioritize real anomalies, minimizing false positives and accelerating response times. Organizations benefit from reduced overlap, streamlined costs, and a stronger overall security posture.
Download the full guide to take the first step towards achieving your next-generation security stack.
[related-resource]
Replacing Your SEG: A Step-by-Step Guide
A practical guide for CISOs for replacing outdated SEGs with AI-driven email security, optimized for Microsoft 365.
.avif)






.avif)