This blog post outlines how Darktrace helps security operations centre (SOC) teams become more efficient by drastically cutting down the time needed to investigate incidents. This is illustrated by an example encountered in a recent Proof of Value where over 350 client devices had been infected by a stealthy banking trojan.
Identifying and investigating a compromise of this size would usually take a SOC team several hours if not days using disparate traditional security tools. Employing Darktrace, the most important questions were answered within 90 minutes. The main reason for this is that Darktrace provides full visibility and context into network activity for all devices monitored on a single, unified platform.
Alert fatigue & the cyber security skill gap
Getting cyber security right is difficult and time-consuming. Complexity is one of the main challenges the cyber security community is facing. These days, networks are only vaguely defined with digital supply chains, outsourcing, the push into the cloud and the advent of micro-virtualisation like Docker. The amount of data stored, devices connected to internal networks, connections made by devices and the heterogeneity in IT adds to this complexity. Managing it is difficult at best and securing it with traditional tools can be a daunting task.
Our industry is struggling with what has been labelled the ‘cyber security skill gap’. The demand for skilled, experienced security practitioners consistently outstrips supply. SOC teams struggle to find the right people for the job and to keep their analysts motivated in the face of a rapidly evolving threat landscape. Alert fatigue and burnout are common symptoms for SOC analysts working long hours and graveyard shifts.
Investigation methodology
Any incident responder will always begin by asking some high-level questions concerning the incident under investigation – regardless of it being an adware infection, a banking trojan, ransomware, an active intrusion or any other form of cyber security incident.
The most important questions usually are:
- How did the infection occur? (To prevent the same initial infection vector in the future)
- What behavior is the infected device exhibiting? (To understand the threat and the risk of the infection)
- What Indicators of Compromise (IoC) are seen? (To update other security tools and to use for further investigation)
- Are other devices infected as well? (To assess the extent of the infection)
We did a recent Proof of Value with an IT service provider in EMEA. Darktrace entered an environment which had already succumbed to a widespread compromise – over 350 client devices had been infected with banking trojans. Let’s walk through how we identified, triaged and investigated this infection using Darktrace.
Identifying the incident
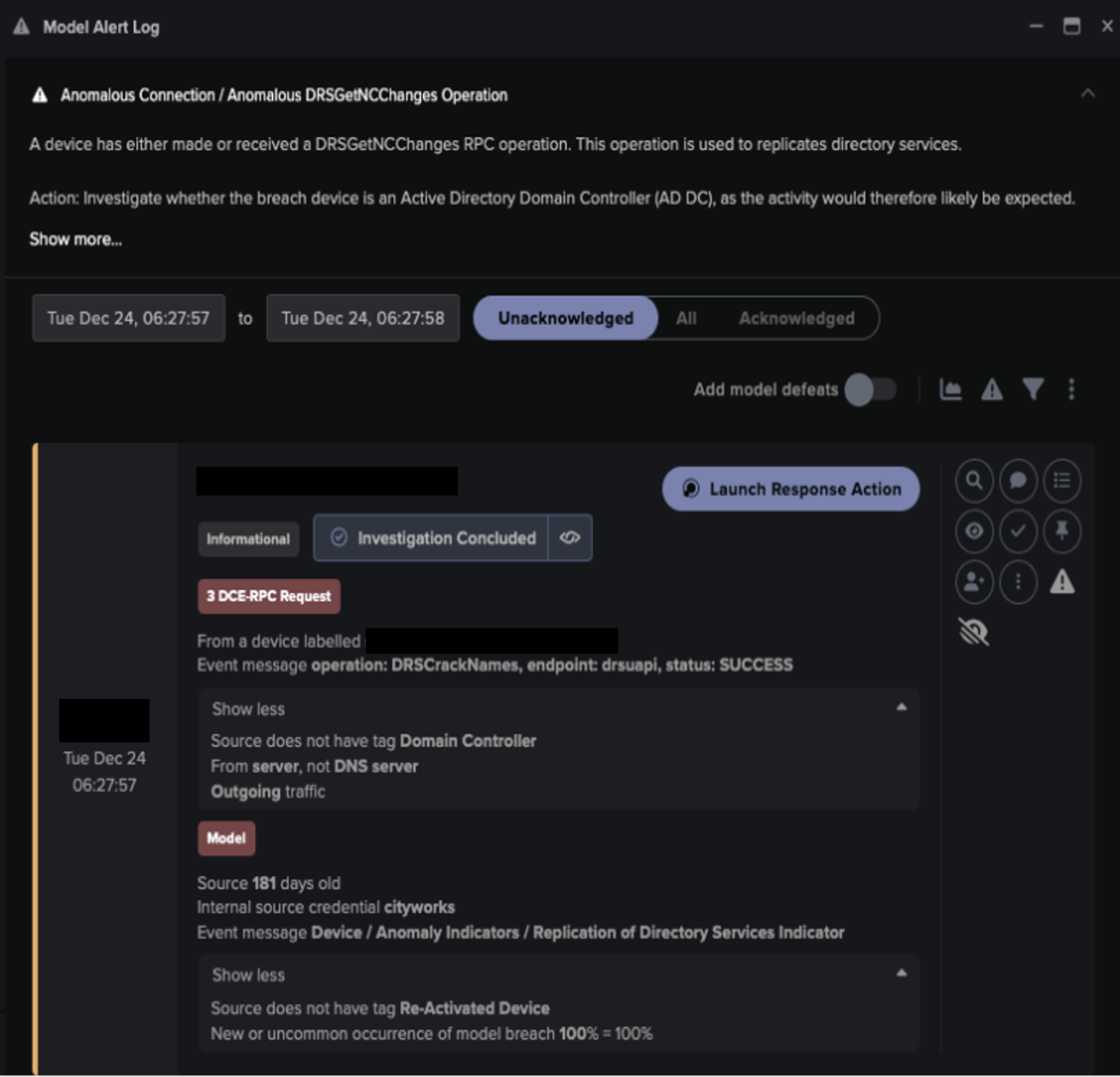
Darktrace came into the environment after the initial infection had taken place already. Darktrace instantly identified several devices exhibiting unexpected HTTP beaconing to unusual, rare external IP addresses. The devices made HTTP POST requests without prior GET requests along other suspicious behavior. Darktrace created several high-severity alerts for this, e.g. ‘Compromise / Suspicious HTTP Beacons to Dotted Quad’ and ‘Compromise / Possible Malware HTTP Comms’:
Figure 1: Example Darktrace alert.
Triaging the incident
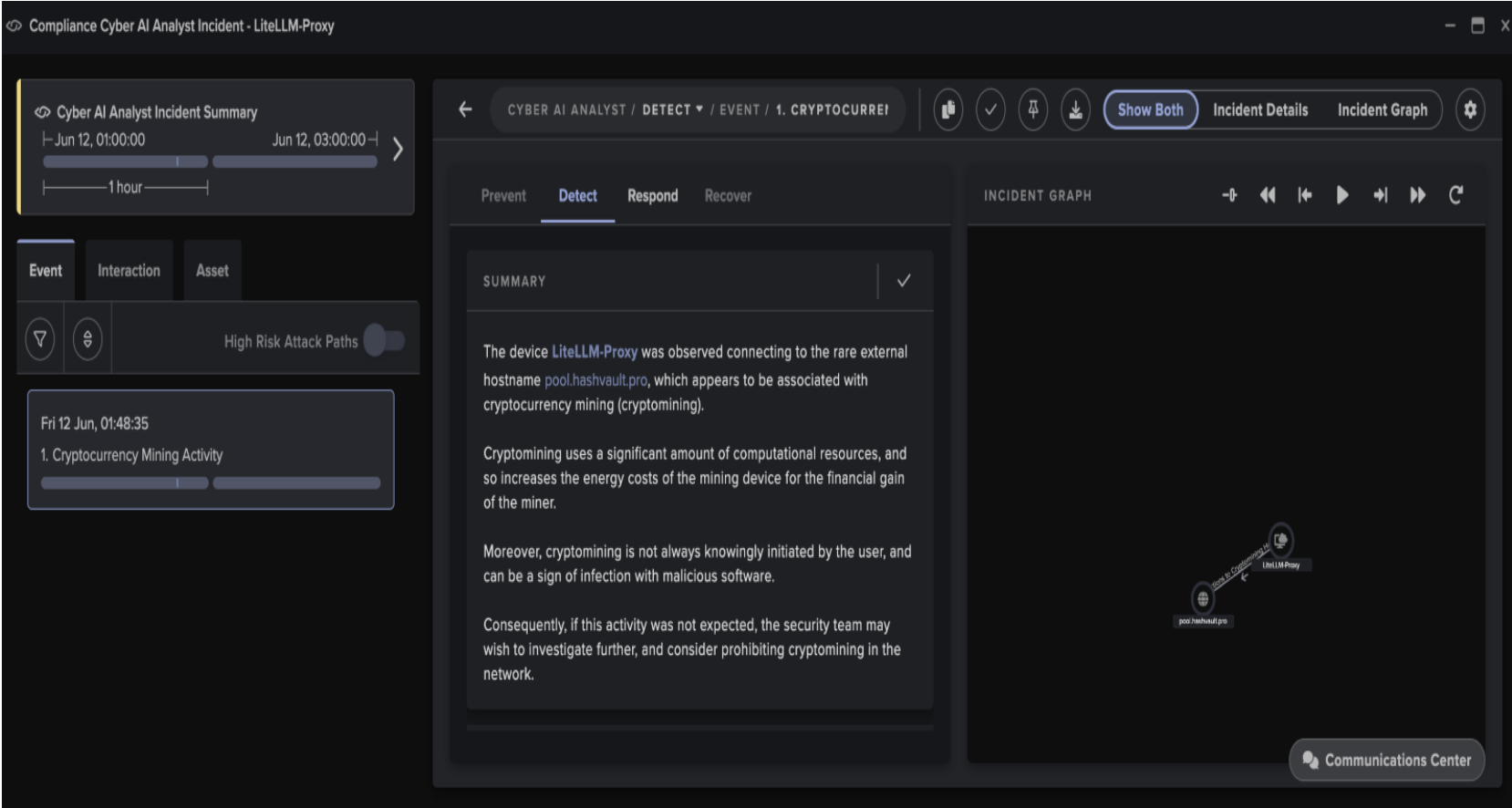
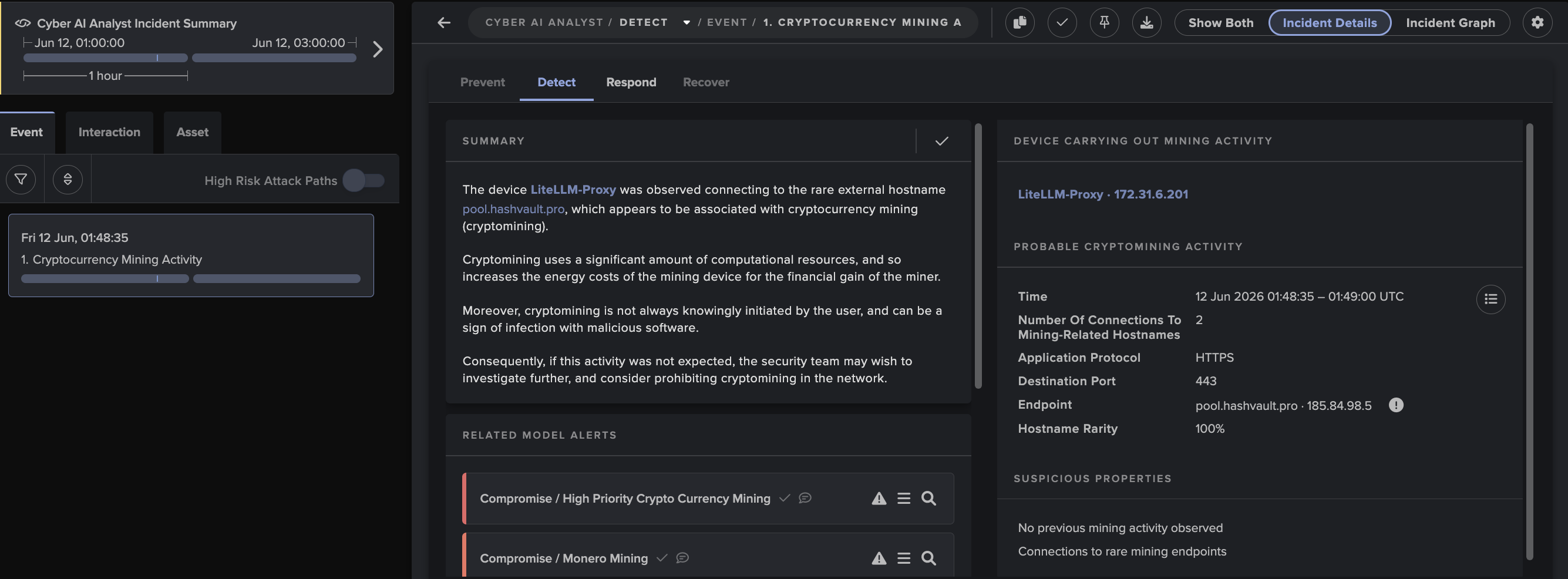
Darktrace then provides context around this alert - e.g. the external IP the beaconing was made to, the internal device including the associated user, and the suspicious behavior:
Figure 2: Detection context and C2 IP.
A quick investigation of the external IP reveals that it is a recently discovered command and control (C2) IP address for the Dridex banking trojan.
Drilling deeper into this, Darktrace provides PCAPs for every connection seen. A PCAP for the C2 connection above confirms this incident as active, successful, encoded beaconing to a malicious C2 IP:

Figure 3: PCAP and encoded HTTP POSTs.
Investigating the incident
At this stage, we want to further examine the behavior of the infected device around the time of the incident. Darktrace provides full visibility into past activity, including all network connection made by any device - regardless of whether the incident occurred on the device or not.
We attend to all external connections made by the infected device around the time of the incident and immediately identify more suspicious C2 communication:
Figure 4: More device behavior; further C2 IPs.
By now we have identified 6 different C2 IP addresses.
We can use Darktrace’s ‘External Sites Summary’ to view all devices that have connected to a specific IP or domain in the recent past. Doing this for the initial C2 IP yields the following result (excerpt):
Figure 5: External Sites Summary; further infections.
We immediately identify 5 additional devices that made successful connections to the C2 IP address. In fact, the list above is abridged as we actually saw over 350 devices connecting to this and other C2 IP addresses. Notably, all observed devices appear to have a similar naming structure - this will become important in the next part of the analysis.
At this point we have answered all but the first question: ‘How did the infection occur?’
Darktrace started monitoring the network after the initial infection occurred and spread. Further research into the C2 IP addresses shows that they are associated with the Emotet trojan. This sophisticated malware often precedes banking trojan (e.g. Dridex) infections and is spread via phishing. We can thus assume that phishing was a likely initial infection vector.
How then did the infection manage to spread to so many devices?
Surely not all users clicked on suspicious phishing emails? Recent versions of Emotet have limited lateral movement capabilities. They mainly propagate via SMB brute forcing - trying administrative accounts and hard-coded password lists. The naming convention on the infected devices is very similar - this could indicate a similar build-process and setup of the devices. If a vulnerability - such as an administrative account with a weak password - existed on one of the devices, it might be present in all of the devices with a similar build.
Using Darktrace, the security team has now a solid understanding of the nature and size of the infection, the IoCs available to update firewalls and other preventive security controls and outstanding remediation-activities.
What would this investigation look like with traditional tools, not using Darktrace?
Detecting these covert banking trojans in the first place, let alone triaging them fully, can be a difficult challenge in itself. Current banking Trojan strains such as Dridex, Fedeo or Vawtrak keep updating the malware with new C2 addresses to avoid blacklisting. Initial detection could be at any stage of the attack lifecycle – likely it will be in the latter stages though, when considerable damage has already been done.
An analyst will have to log into various security devices to get close to the same level of visibility provided in Darktrace – web proxy logs, anti-virus logs, running PCAPs on infected hosts, SIEM logs. Having to switch between all those disparate security tools is not time-efficient and produces a fragmentary picture of what actually transpired.
Conclusion
A working hypothesis is that a single device was initially infected via phishing, allowing Emotet to spread to over 350 internal devices via SMB brute forcing. It took no longer than 90 minutes to come from an initial detection of the incident to this conclusion, which forms the basis for an actionable report.
The last thing a SOC needs is yet another tool producing a profusion of alerts. Using Darktrace’s machine learning and unrivalled network visibility, you can focus on the small set of relevant alerts and rapidly investigate those incidents according to their severity and priority.
Darktrace can reduce costs even if you bring in a third-party incident response team. You will be able to significantly speed up their ongoing investigation if they have access to Darktrace. Third-party incident response teams are expensive – their daily rates ranging between £2,000 and £3,000 per day. Cutting their work down from days to hours will result in cost and efforts saved.