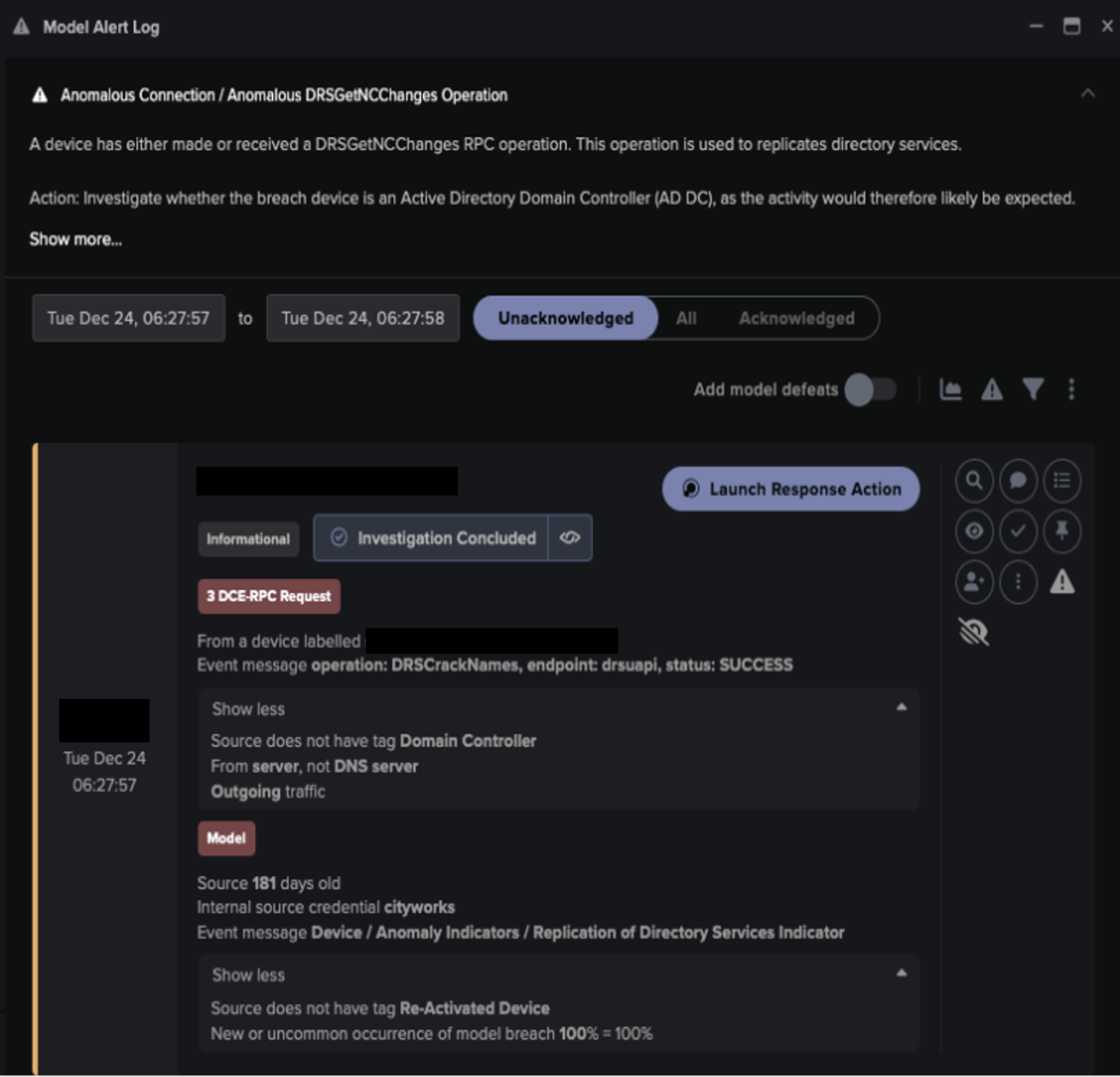
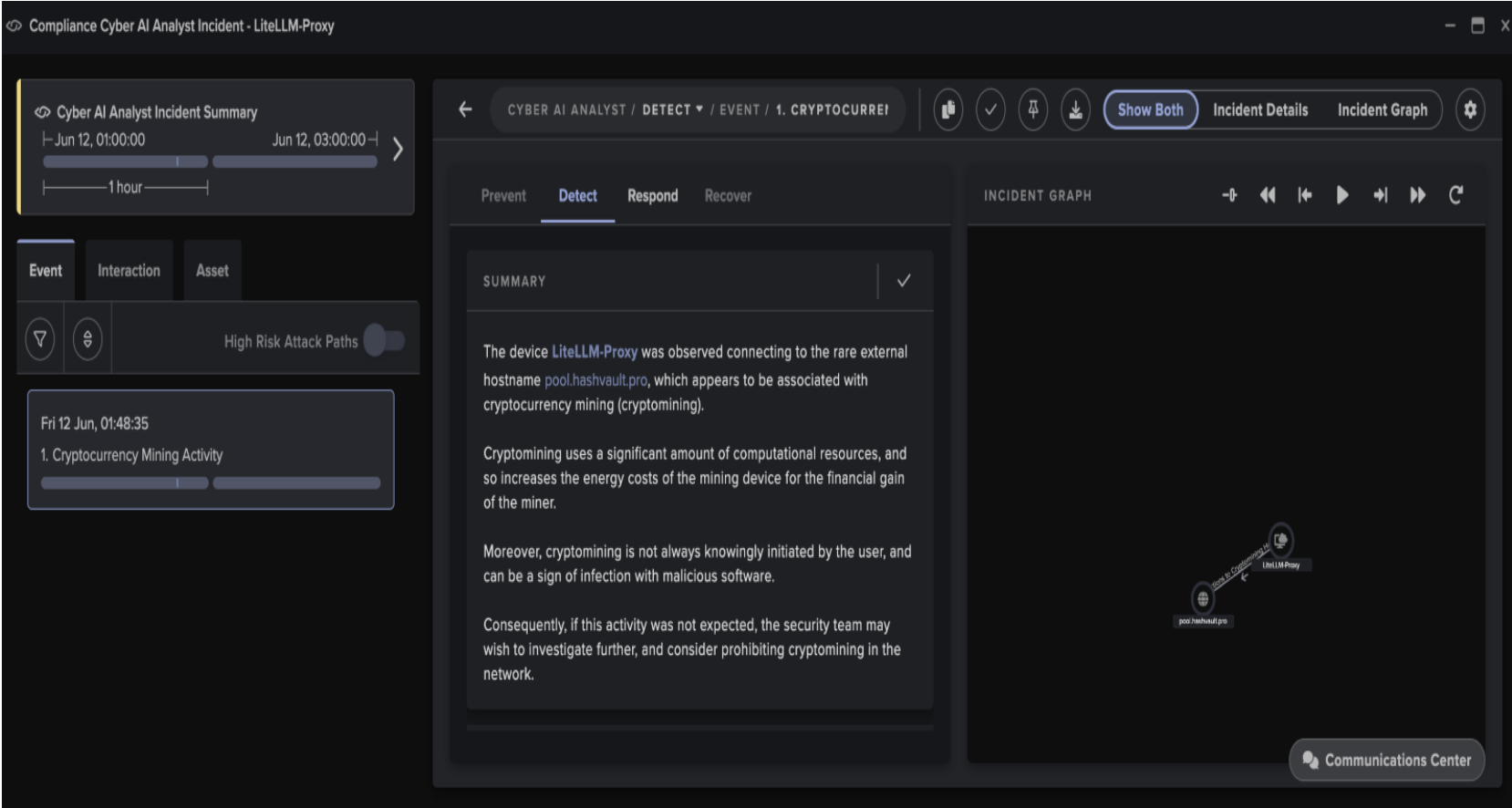
Darktrace was recently called into a situation where a department had set up an online questionnaire, which had been included in a newsletter to customers. They’d used a free version of the software and it had not been authorised by IT.
The questionnaire requested some sensitive data from the respondents, but as there was no third-party contractor agreement in place, there was no agreement on data usage, storage, protection or maintenance. Unfortunately, the software provider had a security vulnerability in their solution, and this resulted in a massive data breach of the questionnaire answers – a situation that could have been avoided, had the organization been using Darktrace PREVENT.
This type of unauthorized usage is a common instance of the growing problem of shadow IT. Unlike formal IT, which is routed through an IT department closely involved in approving, setting up, and maintaining it, shadow IT falls outside of that team’s control. It is made up of systems – including cloud and SaaS applications – which the IT department are either unaware exist, or are unable to remove without disrupting workflows.
Because it lacks proper involvement from IT, shadow IT’s impact on a company’s overall security risk can be ill-defined, not least because it is difficult for many organizations to know how much of it exists within their digital estates. Full visibility over the digital environment, and every asset it contains, is necessary before the problem can begin to be addressed.
The reality is: shadow IT happens
Shadow IT crops up for a number of reasons. This is often employees taking steps to save time: having your IT team acquire and set up new infrastructure and software is important for managing security risks, but they necessarily take time. For some employees, the time taken to go through these formal channels is enough to push them to use shadow IT systems, which are generally quicker and cheaper to set up and begin using. It’s easier than ever, for instance, to spin up cloud IT environments. The pressure of completing projects within strict budgetary limitations may also tempt employees down this cheaper, but more hazardous path.
There is also a problem of business-led IT, whereby business decisions involving the use of new systems are made without consulting IT departments. Organizations should always look to adopt a security-first approach, because when business interests lead the way, IT teams can struggle to keep up, leading to the emergence of new vulnerabilities. In cases where these business decisions are intentionally hidden from the IT team, Shadow IT becomes a serious concern.
Reducing the effects of Shadow IT
In the end, security teams, particularly those charged with securing large organizations, will never entirely prevent employees from occasionally turning to unauthorized systems. They can, however, reduce the impact that these systems have on the organization’s overall risk landscape.
One way to do this is to reexamine the organization’s workflows. Try to identify which formal processes are unnecessarily cumbersome, forcing employees to work around them, and figure out whether they can be improved. When properly managed, formal adoption of the Shadow IT systems employees are already using can be an effective solution.
Improving workflows in this way will begin to help to address the problem, but it will not be the first step an organization takes in the fight against Shadow IT: first it must discover that it has a problem that needs solving, and this cannot be done until its security team uncovers the sheer amount of shadow IT lurking within the organization. The first step, therefore, is to find a way of obtaining total visibility over every system in the digital environment.
The Power of Prevention
For years Darktrace has illuminated the assets silently lurking within an organization, and now Darktrace / Attack Surface Management is finally giving security teams a clear and complete view over the external attack surface of their digital estates, including all of the shadow IT they didn’t previously know about. It does so by continuously monitoring assets and connections on the attack surface for risks and vulnerabilities. On average, this process reveals 30-50% more externally-facing assets than were previously known to the organization’s IT team and, importantly, analyzes the respective risk posed by each.
This information is visualized for the security team in a way which makes it simple to determine the ownership of each system and asset, and helps teams to prioritize those vulnerabilities which require the most attention.
This was crucial recently for an organization that had just been hacked through a shadow IT website created by the marketing department, without the knowledge of the security team. The company immediately brought on Darktrace / Attack Surface Management (ASM) to increase their cyber resilience, and the technology identified 12 urgent vulnerabilities due to shadow IT and misconfigurations which allowed the company to plug those holes before a repeat event occurred.
But having a holistic understanding of the risks of shadow IT requires looking beyond the external attack surface. To this end, Darktrace / Proactive Exposure Management identifies and evaluates all of the attack paths which exist in an organization, and reveals unknown devices which may sit along them. These devices may prove to be components in the middle of critical attack paths leading to precious data or vulnerable assets, but Darktrace minimizes this risk by identifying them and assessing the risk they pose to the environment.
At another organization, Darktrace recently identified a disaster recovery domain controller that was supposed to be an exact replication of the production domain controller. Being a standby for the main domain controller, this device was not regularly monitored by the IT team. However, Darktrace continuously monitors assets within a customer’s environment and identified that, even though they should in theory be the exact same, the back-up domain controller had different potential damage scores due to a Microsoft patch failing to install. No one in the IT team had identified this risk, with Darkrtace identifying the need for patching before to avoid the vulnerability being exploited – and critical data falling into the wrong hands.
From there, it’s up to security teams how they wish to proceed. Some systems and assets may pose too great a risk and will need to be closed off, while others, particularly those which are already widely used within the organization and can be easily secured by the IT department, may be allowed to stay. What matters, is that the ‘shadow’ of shadow IT – the element of mystery which makes these systems such a hazard to security teams – has been lifted. With full visibility over every system and asset, and a clear understanding of which ones constitute network vulnerabilities, security teams no longer need to live in fear of their own organization’s digital environments.